Distributing Events via Kafka
This provides an overview of setting up a Kafka-driven pipeline to collect events from a mobile application, processing them with a Faust streaming application, then syndicating raw and processed events to HDFS and ElasticSearch respectively. Finally Kibana provides a simple visual interface for exploring and seeing processed events.
The hypothetical use-case that we are looking to implement is the following: Employees within a Store indicate current store state (e.g. SKU out-of-stock or missing promotional material), these notification events are sent to an application REST back-end and then provided to Kibana as a Producer. All events are syndicated to HDFS for “data lake” storage. Additionally, a Streaming App applies business rules to incoming events and syndicates a subset of events into special handling queues where downstream Consumers can act on incoming events. The “processed events” are additionally passed to Elasticsearch and visualized via Kibana for use-case insights and management.
System infrastructure overview
The end-to-end system can be visualized as:
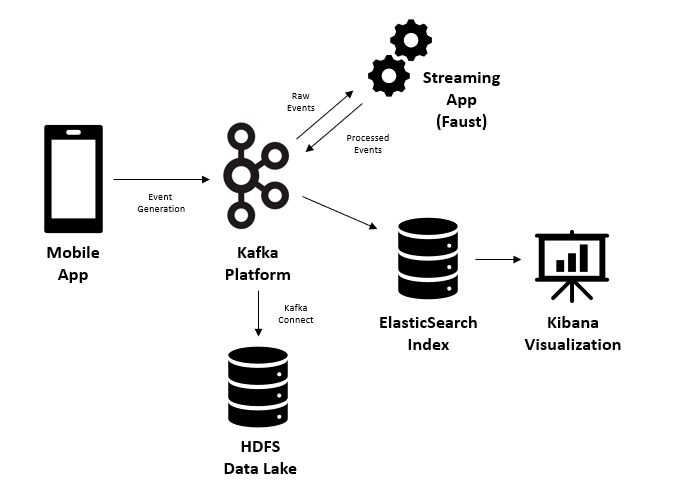
Deploying Docker-based infrastructure
Kafka (Confluent Platform)
We will start using the Confluent Platform all-in-one Docker Compose file indicated in the Confluent Quick Start documentation.
https://raw.githubusercontent.com/confluentinc/cp-all-in-one/7.1.1-post/cp-all-in-one/docker-compose.yml
The advantage of the Confluent Platform all-in-one Docker Compose file is that it will give us an initial Kafka Broker system, as well as supporting systems like Confluence Control Center and an initial Kafka Connect server.
We can go ahead and launch our Kafka Platform via
docker-compose up -d
Navigating to http://localhost:9021/clusters should give you access to the Confluence Control Center.
Updating Kafka Connect with Additional Connector Plugins
The default Kafka Connect server that comes with the docker-compose file is very limited including a few generic Source Connectors. For our use-case we would like to also install the HDFS 3 Sink Connector and the ElasticSearch Sink Connector. It took me an embarrasingly long time to figure out how to do this ;)
In order to add these Sink Connectors to the Kafka Connect Server we will replace the image referenced in the docker-compose with an updated image.
Existing docker-compose defintion:
connect:
image: cnfldemos/cp-server-connect-datagen:0.5.3-7.1.0
hostname: connect
container_name: connect
depends_on:
- broker
- schema-registry
ports:
- "8083:8083"
...
We will build a new image based on the cnfldemos/cp-server-connect-datagen:0.5.3-7.1.0 with additional Connectors installed. First we create the Dockerfile:
FROM cnfldemos/cp-server-connect-datagen:0.5.3-7.1.0
ENV CONNECT_PLUGIN_PATH = "/usr/share/java,/usr/share/confluent-hub-components"
# Add additional Connectors
RUN confluent-hub install --no-prompt confluentinc/kafka-connect-hdfs3:1.1.10 \
&& confluent-hub install --no-prompt confluentinc/kafka-connect-elasticsearch:11.1.10
CMD /etc/confluent/docker/run
We can the build the Dockerfile into a new image with:
docker build -t kafka-connect-sinks .
And then update the docker-compose file to reference our new image:
connect:
image: kafka-connect-sinks:latest
hostname: connect
container_name: connect
command: /etc/confluent/docker/run
depends_on:
- broker
- schema-registry
ports:
- "8083:8083"
...
Now when the Connect Server launches it will have the required HDFS 3 Sink and ElasticSearch Sink files installed and available for configuration.
When viewed in Control Center you should now see these Connectors available for use:
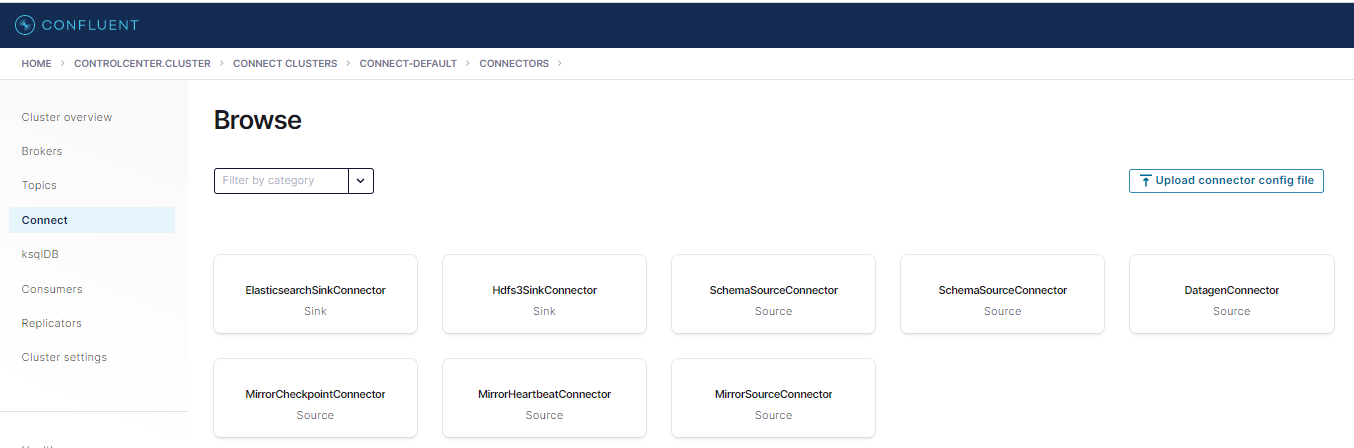
You can also view available Connector Plugins via the Connect Server API endpoint:
http://localhost:8083/connector-plugins/
ElasticSearch & Kibana
We will now add ElasticSearch and Kibana docker containers. These need to be added to the same docker-compose file so that they will be deployed to the same default Docker network (or you would need to arrange for network connectivity between deployments).
Add the following service definitons to the docker-compose file:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch-oss:7.4.0
container_name: elasticsearch
ports:
- 9200:9200
environment:
- discovery.type=single-node
kibana:
image: docker.elastic.co/kibana/kibana-oss:7.4.0
container_name: kibana
ports:
- 5601:5601
HDFS
We can use the existing big-data-europe docker compose defintions via:
git clone https://github.com/big-data-europe/docker-hadoop
We can add the service definitions from the docker-hadoop/docker-compose.yml file as well as copy the hadoop.env file into project directory. Finalized docker-compose.yml can be found in project repo.
Updating deployment
Running docker-compose up -d again will deploy the new additions to the docker-compose.yml file so that we now have Kafka, an updated Kafka Connect server, Elastic Search, Kibana and HDFS services within the Docker created network.
As usual, the deployment can be removed with docker-compose down or individual services can be stopped via docker stop <container_name>. Log files from individual services can be viewed with docker logs <container_name>.
Configuring Environment
Adding Kafka Topics
We will create 2 topics for illustrative purposes:
raw_events- will be topic for all events generated from App.processed_events- will be topic for events identified by Streaming App.
Actual application may have significantly more topics to represent more complexity in routing. In this case we can use the Confluence Control Center to add the topics.

Adding Kafka Connectors
Previously we have added Connector Plugins for HDFS and ElasticSearch but now we need to actually configure specific Connectors to enable the Sinks from Kafka topics to HDFS and ElasticSEarch respectively.
These Connectors can be configured via the Control Center UI or directly via Kafka Connect API endpoints as shown below.
Configuring the HDFS Sink Connector:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "hdfs3-raw-event-sink",
"config": {
"connector.class": "io.confluent.connect.hdfs3.Hdfs3SinkConnector",
"tasks.max": "1",
"topics": "raw_events",
"hdfs.url": "hdfs://namenode:9000",
"flush.size": "3",
"confluent.topic.bootstrap.servers": "localhost:9092",
"confluent.topic.replication.factor": "1",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"schema.ignore": "true",
"key.ignore": "true",
"format.class":"io.confluent.connect.hdfs3.json.JsonFormat"
}
}'
Configuring the ElasticSearch Sink Connector:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "processed-elasticsearch-connector",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"connection.url": "http://elasticsearch:9200",
"tasks.max": "1",
"topics": "processed_events",
"type.name": "_doc",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"schema.ignore": "true",
"key.ignore": "true"
}
}'
Note that both connectors are expecting Kafka values that can be serialized and deserialized as JSON payloads (e.g. value.converter field value). The HDFS sink will store JSON files directly into HDFS (e.g. format.class field value).
You should now be able to view both configured Connectors in Control Center:
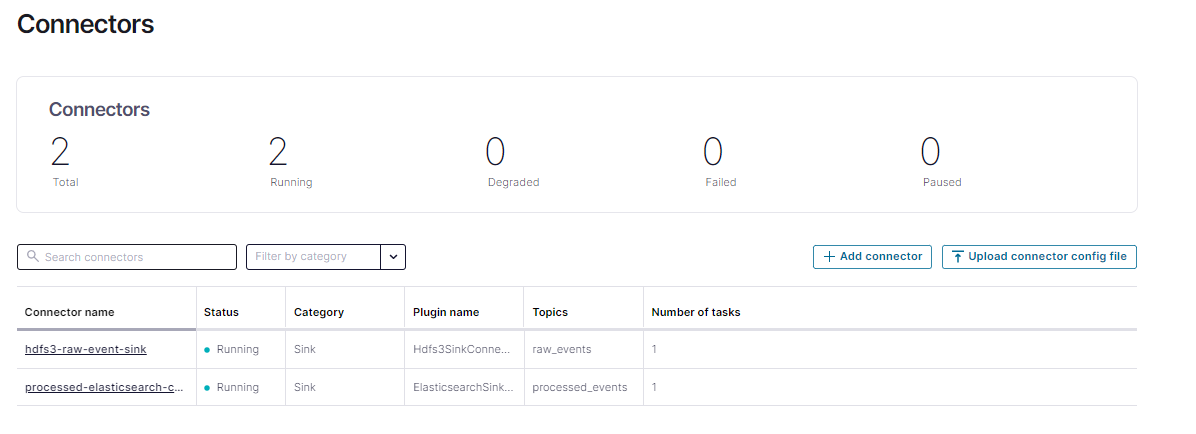
Or can be viewed via the Connect API:
http://localhost:8083/connectors/
If issues arise with configuring Connectors (i.e. tasks fail) then troubleshooting can be done via inspection of Connect Server logs with the docker logs -f connect command.
Creating Streaming App with Faust
We will use the Faust Python library to create a Kafka Streaming Application.
import faust
# Applicaiton event schema definition
class Event(faust.Record):
deviceid: str
timestamp: str
event_type: int
event_status: str
app = faust.App("event_processing_app", broker="kafka://localhost:9092")
raw_events = app.topic("raw_events", value_type=Event)
processed_events = app.topic("processed_events", value_type=Event)
flagged_status_types = ["warning", "error"]
# Example business logic implementation to route events between topics
@app.agent(raw_events, sink=[processed_events])
async def event(events):
async for event in events:
print(f"Processing type: {event.event_type}, status: {event.event_status}")
if event.event_status in flagged_status_types:
print("Sinking event to processed_events.")
yield event
if __name__ == "__main__":
app.main()
Once you have installed the faust-streaming library via pip install faust-streaming you can launch the Streaming Applicaiton via faust -A <app_file_name> worker -l info.
A Dockerfile can be created to enable deployment of the Streaming App:
FROM python:3.8-slim-buster
RUN apt-get update && apt-get -y install git && apt-get -y install curl && apt-get -y install nano
# Update PIP & install package/requirements
RUN python -m pip install --upgrade pip
RUN pip install faust-streaming
RUN pip install requests
# Copy application files:
WORKDIR /app
COPY . /app
# Execute the machine learning pipeline:
CMD faust -A streaming_app worker -l info
And image built via docker build -t kafka-faust ..
and the following service definition can be added to project docker-compose file:
streaming-app:
image: kafka-faust:latest
depends on:
- broker
container_name: streaming_app
network_mode: "host"
Note that the service is actually deployed to “host” network_mode so that advertise Broker endpoints (“localhost”) will function correctly even though Streaming App is deployed into container.
Mock Application Event Generation
We will create an Event Generator that can provide a “mock” implementation of our REST Api that results in production of events into Kafka topic. The events will be encapsulated in an Event class containing the following attributes.
- deviceid - representing an originating device
- timestamp - time of event creation
- event_type - representing a particular type of event (for business logic routing)
- event_status - representing an event status (warning, info, debug)
Event class implementation below:
class Event:
"""Event class for application events."""
def __init__(self, deviceid, timestamp, event_type, event_status) -> None:
self.deviceid = deviceid
self.timestamp = timestamp
self.event_type = event_type
self.event_status = event_status
Alternatively the Kafka Connect Data Generator Source could be used as a Mock Application input.
Generating Events
Seeding initial events
The app/generator.py program can be used to generate initial events into the raw_events topic (arguments -ec = event count to generator, -tc = threads to use for generation). Events will be randomly generated with pauses between each event.

The running streaming app can be monitored with docker logs -f streaming_app. Console output shows individual events being processed as soon as added to topic by generator application. Events matching business logic criteria are then syndicated to processed_events.
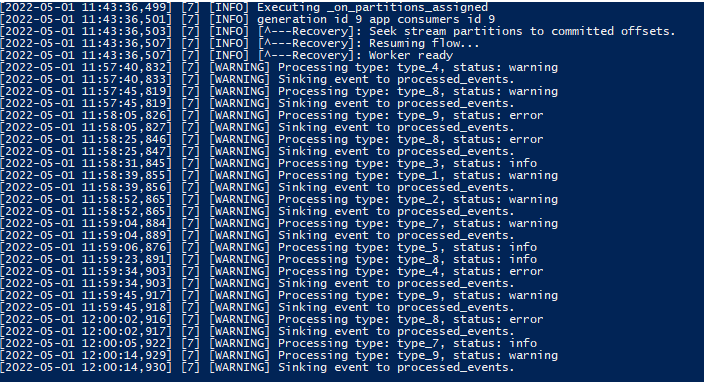
We can confirm that all events have been added to raw_events and processed_events via Control Center:
HDFS Raw Events Storage
We can check in HDFS to make sure that all raw_events are being syndicated to HDFS via the HDFS Sink.
Connect to Hadoop NameNode container:
docker exec -it -u 0 namenode bash
List .json files in HDSF topic directory:
hadoop fs -ls /topics/raw_events/partition=0
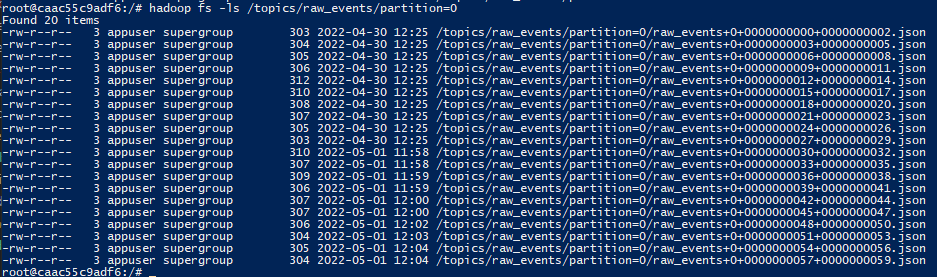
Elastic Search Index
We can similarly confirm that events are being syndicated to ElasticSearch via ElasticSearch API:
curl localhost:9200/processed_events/_search | jq
We could also use Kibana “data explore” functionality to view index:
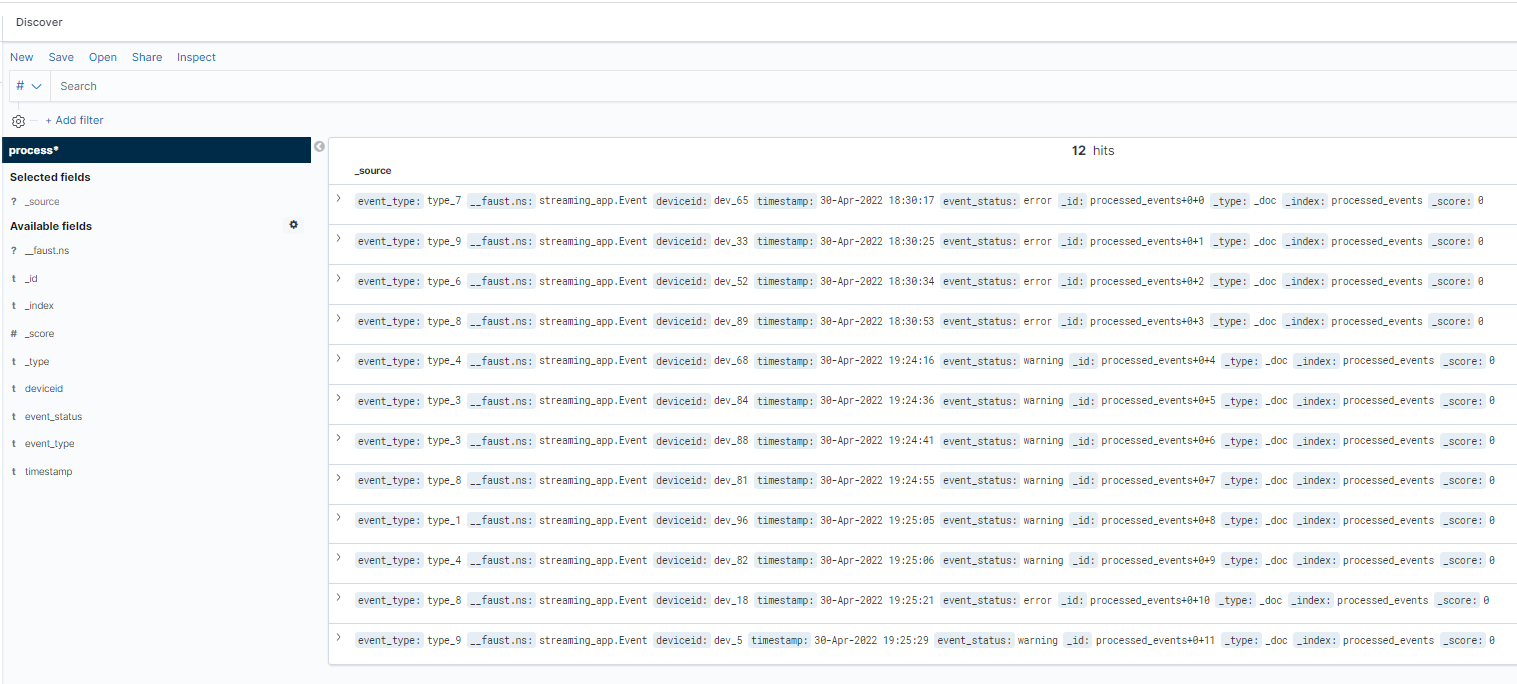
Kibana Dashboard Visualization
For final aspect of architecture we can create a Dashboard to visualize the processed events syndicated to ElasticSearch.
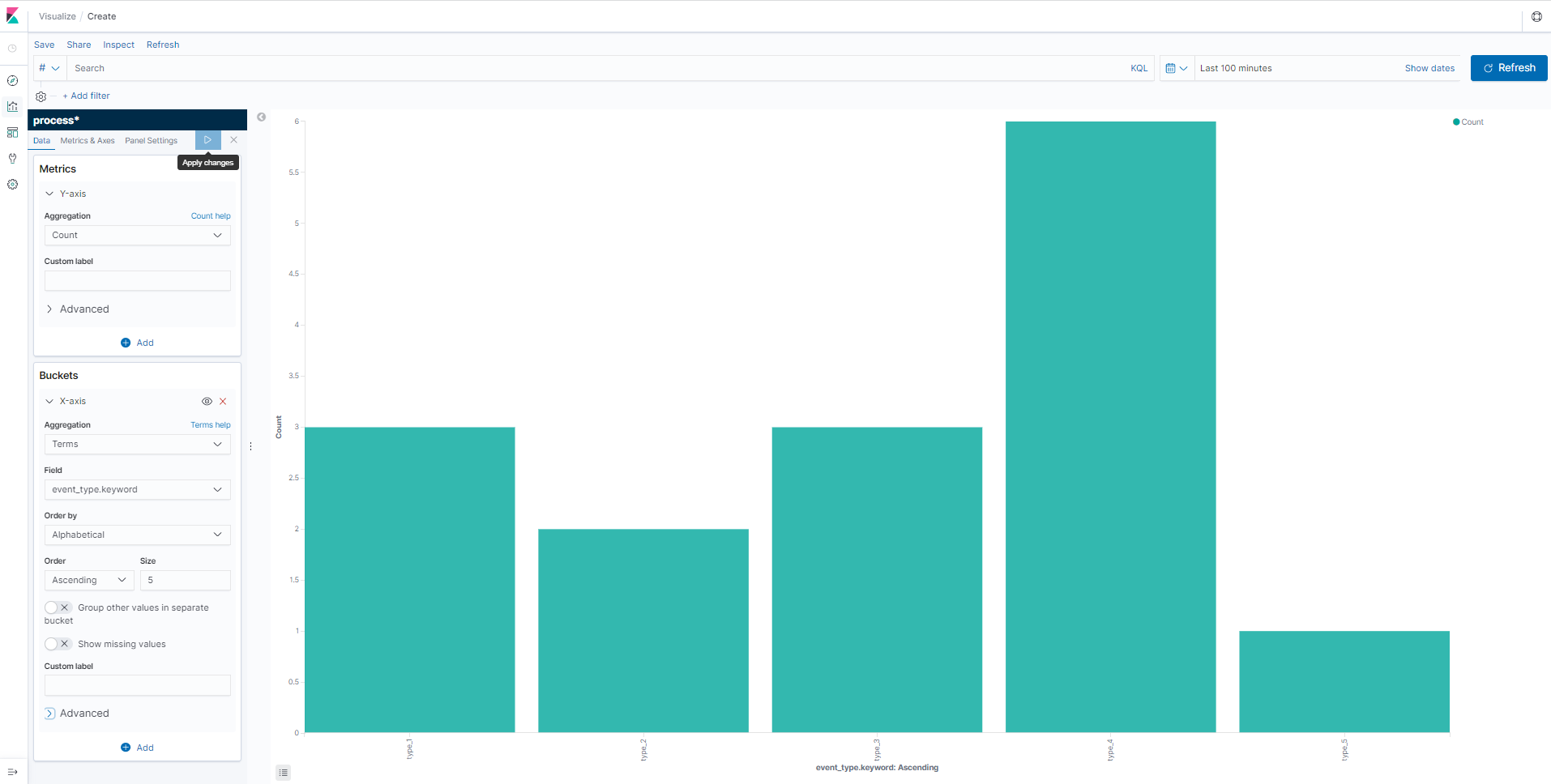
As new results are syndicated the dashboard updates in real time.
Summary Files
Project files can be found in GitHub Repository.