Integrating Great Expectations with MongoDB and PySpark
This project was produced as part of the final project for Harvard University’s CSCI-E59: Designing and Developing Relational and NoSQL Databases course. A summarization presentation on the below can be found here.
Context
Data Science algorithms and Business Intelligence reporting are contingent on having accessible, high-quality data. Data Engineers strive to create fit-for-use ETL/ELT data pipelines but often neglect to integrate Data Quality management into pipeline devOps processes.
As discussed in previous posts - Great Expectations provides a user-friendly, extensible framework for building “expectations” for your data as it flows through pipelines.
To drive enterprise-level use of Great Expectations we will illustrate integration of Great Expectations into PySpark Data Frame creation as well as the scalable storage of Expectation validation results using MongoDB backend. Additionally we will illustrate integration of PySpark ability to read from MongoDB using the MongoDB Connector for Spark.
Our goal is to create a scalable approach for Data Quality management that can be integrated directly into existing PySpark/Databrick development practices.
Background: Great Expectation Validation Result Data
Great Expectations is able to produce summarizations of validations that are applied to data sets in a resulting JSON format.
An example of a generated validation result may look simliar to the following, containing mulitple nested structures that vary depending on the specific expectations that are used:
{
"meta": {
"great_expectations_version": "0.16.11",
"expectation_suite_name": "default",
"run_id": {
"run_time": "2023-05-06T09:10:46.463914-04:00",
"run_name": null
},
"batch_kwargs": {
"ge_batch_id": "67c85968-ec0f-11ed-a321-00155d29b44d"
},
"batch_markers": {},
"batch_parameters": {},
"validation_time": "20230506T131046.463646Z",
"expectation_suite_meta": {
"great_expectations_version": "0.16.11"
}
},
"evaluation_parameters": {},
"results": [
{
"expectation_config": {
"meta": {},
"expectation_type": "expect_column_to_exist",
"kwargs": {
"column": "id",
"result_format": "BASIC"
}
},
"meta": {},
"exception_info": {
"raised_exception": false,
"exception_message": null,
"exception_traceback": null
},
"result": {},
"success": true
},
{
"expectation_config": {
"meta": {},
"expectation_type": "expect_column_values_to_be_unique",
"kwargs": {
"column": "id",
"result_format": "BASIC"
}
},
"meta": {},
"exception_info": {
"raised_exception": false,
"exception_message": null,
"exception_traceback": null
},
"result": {
"element_count": 4,
"missing_count": 0,
"missing_percent": 0.0,
"unexpected_count": 0,
"unexpected_percent": 0.0,
"unexpected_percent_total": 0.0,
"unexpected_percent_nonmissing": 0.0,
"partial_unexpected_list": []
},
"success": true
}
],
"statistics": {
"evaluated_expectations": 2,
"successful_expectations": 2,
"unsuccessful_expectations": 0,
"success_percent": 100.0
},
"success": true,
"pipeline_name": "Data-Pipeline"
}
As we think about the scaled management of this data it is important to note:
- Originating JSON format
- Variable Schema
Back-end (Data-base) Assessment
Given the above understanding of data produced by the Great Expectations validation framework, as well as our desire to integrate with existing PySpark-driven processes it makes sense to consider 3 primary options for data serialization.
Relational (e.g. MySQL) Database support
A RDBMS could be used to store the JSON data produced above but would have inherent weaknesses when dealing with the data including:
- Need to “flat map” nested structures into a normalized database schema
- Difficulty maintaining RDBMS schema as different expecations produce different nested values
The difficulty and effort of the above often result in “data loss” when un-structured or loosely structured data is mapped into a highly-structured RDBMS with only currently valued fields being mapped and stored.
Given the above challenges and the obvious disconnect between the JSON/loosely-structured originating data and an RDBMS approach it was not recommended that RDBSM technologies be used for this project.
PySpark + HDFS native support
PySpark does support native read/write for JSON files as part of API:
sc = spark.sparkContext
df = spark.read.json(file_system_path_to_file)
Given the scalable nature of PySpark execution (e.g. horizontal executors reading and writing to a scalable back-end filestore like HDFS) this would be a feasable approach for validation data storage and processing. However there are limitations to Spark support for JSON with some schema inference loading issues seen during experimenation. Additionally while Spark provides a SQL interface that support JSON field references, it does not necessarily provide first-class JSON processing supporting and queries may suffer from increased complexity.
NoSQL (e.g. MongoDB) Database support
NoSQL databases provide native, first-class support for JSON and unstructured documents as part of “collection” management.
Databases like MongoDB enable a seamless store of JSON documents while also maintaining high scalabiliy and availabilty that enable enterprise, production-level use.
Given the clear support for originating JSON data and the ongoing simplification of document management as validation schema changes with expectation use as well as the confidence we can store all “raw” originating data it is determined that MongoDB provides the best back-end to use as part of project end-to-end validation data management objective.
MongoDB Infrastructure
A local deployment of MongoDB + Mongo-Express (web-based MongoDB management utility) was created via Docker using latest mongo and mongo-express docker images.
The docker-compose file can be referenced here. Upon running docker compose up with associated file you should be able to confirm running instances of mongo and mongo-express:

Additionally you should be able to docker exec -it mongodb bash to connect to shell within mongo container and mongosh -u <user> -p to launch MongoShell within container.
Mongo-Express provides a more intuitive, user-friendly option vs. MongoShell providing database, collection and document management support (example screenshot below).
Upon running docker compose up you should be able to access web-ui for Mongo-Express via http://localhost:8081/.
If it isn’t desired to run a local development enviornment, the MongoDB Cloud Atlas service provides free MongoDB instances that can be used as an alternative.
Data Generation via Great Expectations
In order to reflect actual, expected usage a mock data pipeline was created to simulate in-world data validation.
Data Frame Definitions
Great Expectations provides a class to extend Spark DataFrames via the great_expectations.dataset.SparkDFDataset implementation. For this project we use this approach to build expectations directly into Spark DataFrames.
An example of a DataFrame definition can be seen below:
class ExampleInputDataFrame(BaseValidatedDataFrame):
def add_validation_rules(self) -> None:
"""Add validation rules for ExampleDataFrame"""
# Structural Expectations:
self.expect_column_to_exist("id")
self.expect_column_to_exist("color")
self.expect_column_to_exist("letter")
# Schema Expectations:
self.expect_column_values_to_be_unique("id")
self.expect_column_values_to_be_unique("letter")
# Content Expectations:
self.expect_column_mean_to_be_between(column="id", min_value=-3, max_value=3)
@classmethod
def load_dataframe(cls):
"""Implement logic to load dataframe from source"""
spark = SparkSession.getActiveSession()
# Generate Fake Data:
colors = ["Red", "White", "Green", "Blue", "Purple", "Gold"]
color_data = [str(np.random.choice(colors)) for x in range(5)]
number_data = (
np.random.normal(loc=0, scale=10, size=5).round(0).astype(np.int16).tolist()
)
letter_data = [
str(np.random.choice(list(string.ascii_lowercase))) for x in range(5)
]
data = [list(a) for a in zip(number_data, color_data, letter_data)]
df = spark.createDataFrame(
pd.DataFrame(data, columns=["id", "color", "letter"]),
schema="id LONG, color STRING, letter STRING",
)
return df
This class implementation will create a Spark Dataframe consisting of id, color, and letter columns which are populated via a random selection of values. These random values will be validated against defined structural, schema and content expectations defined above. Given the random nature of selection this will produce both successful and unsuccessful validations to provide us with a diverse set of data for experimentation.
Pipeline Execution
The mock pipeline full code-base can be viewed here but for simplicity is summarized below.
Run 1500+ iterations of:
- Select a pipeline name out of 5 potential options to simulate different running pipelines
- Define pipeline characteristics including specifying use of
MongoDBFileStorageserializer to enable write-support for MongoDB as part of pipeline execution - Validate expected inputted Data Frame
- Execute 2 transformation steps to concatenate Data Frame columns and count unique columns
- Validate outputted Data Frame
Running this pipeline over multiple days created a robust set of data for query and reporting experimentation.
MongoDB Serialization Integration
The PyMongo library was used to enable write support to MongoDB as part of pipeline serialization process. The created serializer can be viewed here or below:
from gdh.validation.filestorage import FileStorage
from great_expectations.core import ExpectationSuiteValidationResult
from pymongo.collection import Collection
class MongoDBFileStorage(FileStorage):
"""Serializer interface for MongoDB."""
db_collection: Collection = None
def __init__(self, path, **kwargs) -> None:
"""Initialize Mongodb Serializer.
Parameters:
- path (positional): The connection to MongDB for use.
"""
self.db_collection = path
def save_validation_results(
self, pipeline_name: str, results: ExpectationSuiteValidationResult
) -> None:
"""Save validation results to MongoDB."""
document_id = self.get_serialization_filename(pipeline_name, results)
# Convert to JSON Dict for MongoDB storage:
if isinstance(results, ExpectationSuiteValidationResult):
results = results.to_json_dict()
results["_id"] = document_id
results["pipeline_name"] = pipeline_name
self.db_collection.insert_one(results)
As viewed above the implementation takes a reference to a MongoDB collection and saves an ExpectationSuiteValidationResult to this collection with appended _id and pipeline_name fields.
Resulting Document Collection
Once executed all validation result data is collected within the MongoDB verification_results / pipeline collection for down-stream use:
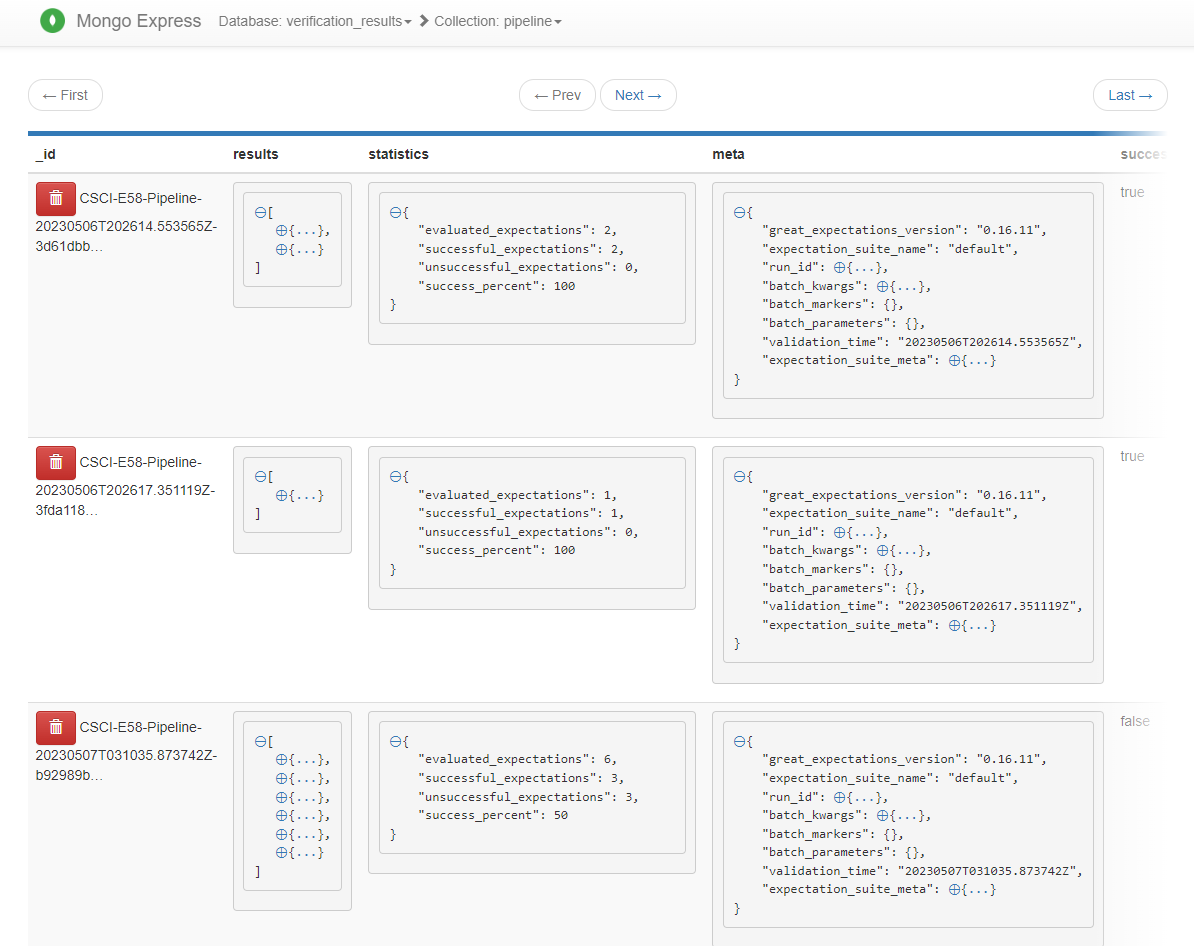
It was determined that all pipeline data should be stored in one collection given that MongoDB provides significant support for filtering, sharding and indexing and limited support for joining across different collections. Having all validation data in one collection does not increase difficulty of reporting on one specific pipeline (scale issues can be sovled via sharding and indexing mentioned later) and greatly simplifies desired reports on total failures across all pipelines.
MongoDB Aggregation Pipelines
With documents now stored in MongoDB collection we can now explore creation of Aggregate Pipeilnes (i.e. views) that can be used to provide descriptive understanding of Data Quality failures (i.e. reporting). In this instance views are created as “non-materialized” so are processed at point of query. If performance issues arise it would be possible to use materialized-views for improved query speed. Code for aggregate pipline queries can be found here.
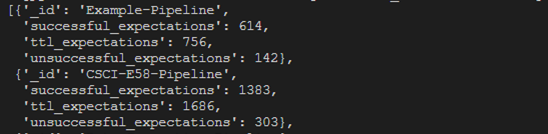
Aggregate Pipeilne #1 - Pipeline Summary Statistics
Our initial query will provide understanding of pipeline historical failure vs. success rate. This pipeline is defined below and effectively groups documents by pipeline_name and uses the existing statistics attribute to sum successful_expectations and unsuccessful_expectations:
{
"$group": {
"_id": "$pipeline_name",
"ttl_expectations": {"$sum": "$statistics.evaluated_expectations"},
"successful_expectations": {
"$sum": "$statistics.successful_expectations"
},
"unsuccessful_expectations": {
"$sum": "$statistics.unsuccessful_expectations"
},
},
},
Example results from this pipeline:
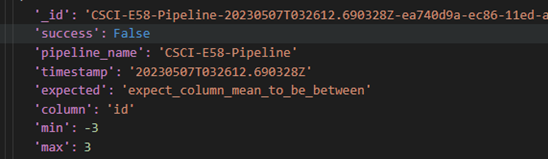
Aggregate Pipeline #2 - List of all Failed Expectations
This pipeline provides a list of all Failed expectations as well as associated column and arguments applied to exepctation. Pipeline definition is below including filtering for failed expectations, “unwinding” to un-nest expectations from document and projecting results to desired fields:
{"$match": {"success": False}}, // Filter to documents that contain a failure
{"$unwind": "$results"}, // Unwind specific expectations
{
"$addFields": {
"success": "$results.success",
"timestamp": "$meta.validation_time",
"expected": "$results.expectation_config.expectation_type",
"column": "$results.expectation_config.kwargs.column",
"min": "$results.expectation_config.kwargs.min_value",
"max": "$results.expectation_config.kwargs.max_value",
}
},
{"$match": {"success": False}}, // Filter expectations that failed
{
"$project": {
"_id": 1,
"pipeline_name": 1,
"success": 1,
"timestamp": 1,
"expected": 1,
"column": 1,
"min": 1,
"max": 1,
}
},
Example results from this pipeline:
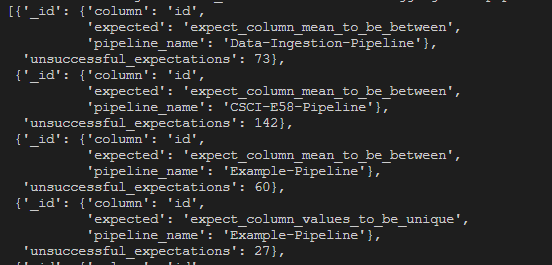
Aggregate Pipeline #3 - Most Common Pipeline Failed Expectations
This pipeline summarizes the above list of all failed expectations to provide a high-level view of what expectations are failing most often for specific pipelines. This appends an additional grouping stage to above pipeline to provide a count of failed expectations per pipeline.
/* Appended as stage to failed list pipeline above*/
{
"$group": { // Group total failures by pipeilne, expectation & column
"_id": {
"pipeline_name": "$pipeline_name",
"expected": "$expected",
"column": "$column",
},
"unsuccessful_expectations": {"$count": {}},
},
}
Example results from this pipeline:
PySpark Data Frame Read Integration
In additional to PyMongo-based queries we can leverage the MongoDB Connector for Spark to directly query MongoDB documents via PySpark APIs. Example pyspark code can be found here.
To enable MongoDB read support the PySpark SparkSession needs to be launched with supporting connect jar. Note that the specific connector version needs to be appropriately matched with Spark (e.g. 3.2.1) and Scala (e.g. 2.12.15) version installed in environment (can be identified via pyspark --version command):
# Create the SparkSession with the
# mongo-spark connector enabled on classpath:
spark = (
SparkSession.builder.appName("Expectation-Failure-Reporting")
.config(
"spark.jars.packages", "org.mongodb.spark:mongo-spark-connector_2.12:10.1.1"
)
.getOrCreate()
)
Dataframes can then be created from MongoDB collection using the “mongodb” format loader:
# Read from Mongodb db/collection into DataFrame
df = (
spark.read.format("mongodb")
.option("spark.mongodb.read.database", os.getenv("VERIFICATION_MONGO_DB_NAME"))
.option("spark.mongodb.read.collection", "pipeline")
.option(
"spark.mongodb.read.connection.uri",
os.getenv("VERIFICATION_MONGO_CONNECTION_STR"),
)
.load()
)
Once made avaiable as a DataFrame standard SparkSQL or DataFrame operations can be applied.
Spark DataFrame Query #1 - Today’s Failures
This query provides a list of pipeline failures that have happened on current day using the meta.validation_time timestamp (converted to Date object) to filter results vs. current date and sort descending:
# Filter to just Failed records:
df = df.filter(F.col("success") == False)
# Report on Failures today:
df_today_failures = (
df.withColumn(
"truncated_timestamp", F.substring(F.col("meta.validation_time"), 1, 8)
)
.withColumn("date", F.to_date(F.col("truncated_timestamp"), "yyyyMMdd"))
.filter(F.col("date") == F.current_date())
.orderBy(F.col("meta.validation_time").desc())
.select(
[
"pipeline_name",
"meta.validation_time",
F.explode("results.expectation_config.expectation_type").alias(
"expectation_type"
),
]
)
)
Note: The pyspark.sql.functions.explode function serves a purpose similar to MongoDB’s $unwind step to un-nest embedded arrays.
Example results from this query:
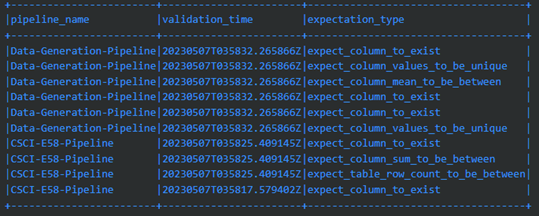
Spark DataFrame Query #2 - Columns with Most Frequent Failures
This query provides visibility to data-set columns that have most frequent failures and associated failure expectation type:
# Filter to just Failed records:
df = df.filter(F.col("success") == False)
# Report on Column failures:
df_col_failures = (
df.select([F.explode("results.expectation_config.kwargs.column").alias("column")])
.groupBy(F.col("column"))
.agg(F.count(F.lit(1)).alias("failure count"))
)
Example results from this query:
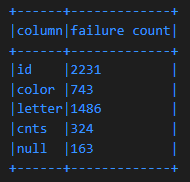
MongoDB Scalability Options
While the default MongoDB configuration provided sub-second responses for all inserts and queries there are additional considerations and factors that could be considered to improve scalabiltiy and production robustness:
- Sharding - Data can be shared over a set of machines to enable large scale data collection management with each distributed machine having responsibility for one “shard” of data. This provides the ability to maintain query performance but increases infrastructure cost and complexity.
- Materialized Views - Aggregate Pipelines can be materialized to reduce on-demand processing requirements (read from disk vs. computing) and reduce query response time. This comes at the cost of increased storage and requirements to define materialize refresh timing.
- Indexing - Indexes can be applied to Collection to improve query filtering by eliminating need for full collection query scans (i.e. reviewing every document). For our queries above key indexes that help improve performance are: success and pipeline_name which are used for failure filtering and individual pipeline reporting respectively.
- Replica Sets - Replica sets (i.e. replication) provides high availability by replicating data (or sharded data) to secondary servers. This insures that if there is a failure with one server there are redundat backups that can maintain alway-on uptime. MongoDB manages replication to maintain synchonization between primary and secondary replicas. While less common, replicas can also improve query performance by providing alternative query sources for high-load, peak periods.