Data Science responsibilities in Data Quality assurance
There is often a question on “who owns data quality assurance” in a ML pipeline - Data Engineering or Data Science? The answer to this question should be both - but it is important to clarify which parts of the pipeline that each organization should own to prevent confusion.
TL; DR
Data Scientists have significant responsibility to monitor data inputted into both Training and Inference pipelines and should establish automated safe-guards to protect against invalid model builds or predictions.
A Composite Approach to ML Pipelines
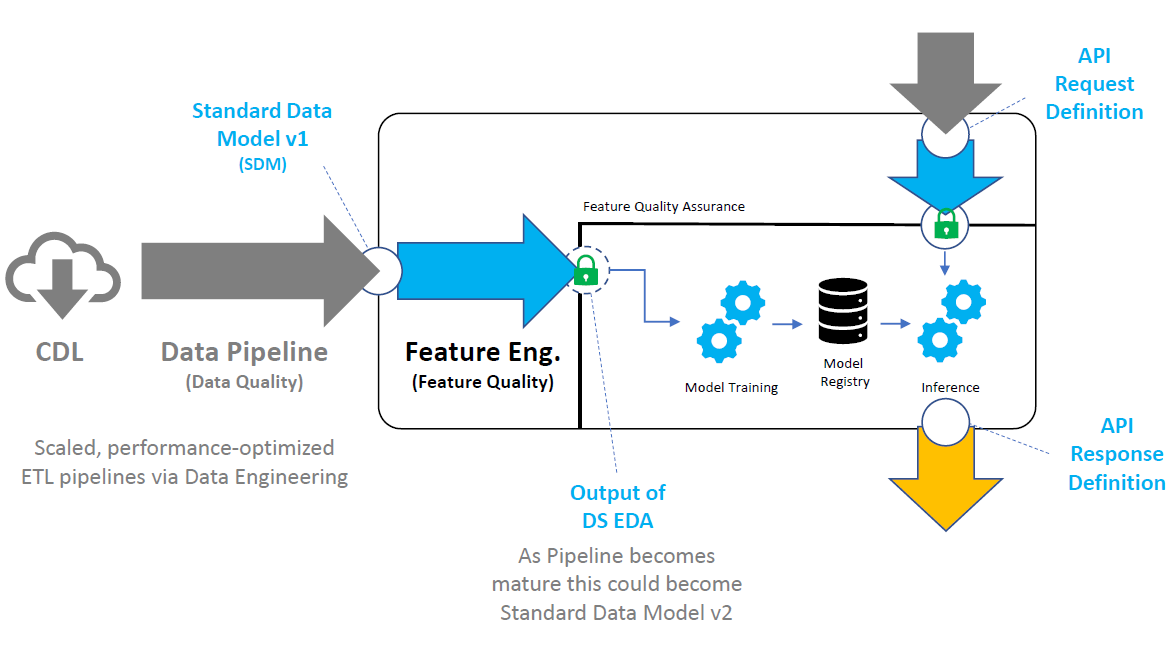
If we consider the key interfaces associated with a composite ML deployment it would include:
- Input Standard Data Model - this defines the structure and format of data expected to be provided to the ML Pipeline for Training.
- API Request Definition - this is the defintion of the API (or data input) expected as input for Inference.
- API Response Definition - this is the definition of the response (or data) expected as output of Inference.
A Data Scientist should be accountable for providing clear definitions of all of the above and should be expected to confirm quality of inputs to make sure they meet Pipeline expectations. For high-value processes, if data expectations are not met then the pipeline should be halted to prevent potentially erroneous model build or inference actions.
Data Quality vs. Feature Quality
To differentiate Data Engineering quality monitoring of the Data Pipeline vs. Feature Engineering produced by the Data Scientist it can be helpful to use specific terminology:
- Data Quality - monitoring output of transforming raw input data from a Data Lake to a Standard Data Model (SDM) aligned with the Data Scientist.
- Feature Quality - monitoring process of Feature Engineering applied to SDM by the Data Scientist to produce a data-set as Training input.
In essence this is simplified as the Data Engineer owns quality of everything “outside” of the composite ML Pipeline (i.e. up to the SDM) and the Data Scientist owns quality of anything “after” the SDM.
Composition of Feature Quality
The implementation of Feature Quality has unique expectations beyond traditional Data Quality assessment and should consider the following aspects:
- Confirmation of any expectations derived from Standard Data Model defintion (e.g. table structure, column types, and input value expectations)
- Confirmation of any expectations derived from Feature Engineering (e.g. incremental columns and expected value ranges)
- Statistical characteristics (e.g. averages, variation, etc.) that is typically incremental to SDM defintion but can impact model quality
Additionally, during “API Request (input) Verification”, Feature Quality should provide a comparison across Standard Data Model and Inference inputs to make sure there is not significant difference of statistical characteristics (e.g. “data or concept drift”). For example you can easily imagine a training data-set where a key input feature X ranged between 0-10 and yet the X provided for inference is 10,000 - this would be a clear mismatch in characteristics between training and inference that would likely lead to an invalid prediction.
Role of Explatory Data Analysis (EDA)
Data Scientists often begin projects with intensive Explatory Data Analysis (EDA) to understand the “strengths and weaknesses” of the data as well as to formulate potential high-value features. Often this understanding gets thrown away (i.e. the Data Scientist abandons the Jupyter notebook used for EDA). Instead this work should be translated into specific rules or checks that are incorporated into a Feature Quality confirmation step within the Pipeline.
Evolution of Standard Data Model
Over time the Data Scientist may update Standard Data Model (SDM) definiton with Data Engineering (v1, v2, v3, …) to include additional Features and thereby eliminate any Feature Engineering within the composite ML pipeline.
In this case the Data Scientist should still establish checks on input to confirm that SDM expectations are being met (trust but verify) as well as key statistical characteristics are stable.
Elimination of Data Scientist created Feature Engineering in pipeline does not remove the need for Data Scientists to establish quality control on data inputs.
Implementing Feature Quality Confirmation
Great Expectations is a python library that enables the creation of expectations (i.e. data validation rules) that can easily be integrated into ML Pipelines.