CIRI Application - Kubernetes (GKE) + TensorFlow
This project was produced as part of the final project for Harvard University’s AC295 Fall 2021 course.

Context
Waste management is one of the most challenging problems to solve in the 21st century.
The average American produces ~1,700 pounds of garbage per year which is roughly three times the global average, according to a report by the research firm Verisk Maplecroft in 2019.
Poor waste management is linked to significant environmental risks, such as climate change and pollution will likely have significant long-term effects to our environment that will impact future generations.
The introduction of a “single-stream” approach to recycling where materials are not pre-sorted into common recycling classes like paper, aluminum, metal, and glass has greatly increased the rate of participation in recycling programs - but has led to substantial incrases in contamination as well.
Recycling contamination occurs when non-recyclable materials are mixed with recyclable materials. Current estimates are that 1 in 4 items inserted into a recycling bin are inappropriate for recycling. Contamination can inadvertently lead to:
- Increased cost of recycling as more effort is required for waste sorting - which can lead to non-viable economic models for local recycling.
- Reduces over-all quantity of recycled material as leads to contamination of recyclable items to the point where they are no longer suitable for recycling.
- Potential damage to recyling equipment or danger to recycling plant employees.
In many cases consumers are unaware of the negative impacts of recycling contamination and are well intented by trying to add items to recycling bins. Additionally the introduction of varied plastics and packaging has led to increased difficulty in identifying recycable vs. non-recylcable items.
Our goal is to develop a prototype application that allows users to easily classify “recyclable” vs. “non-recyclable” materials via a Deep Learning model. The application will be comprised of a multi-tier architecture hosted on Kubernetes (GKE). Application deployment will be via CI/CD integration into project GitHub repositories.
Data

The dataset used for training included 2467 images from Trashnet challenge segmented into 6 human-annotated categories: cardboard (393), glass (491), metal (400), paper (584), plastic (472) and trash (127).
Training dataset was expanded with additional curated images from the Waste Classification v2 dataset which included images labeled as Recycleable, Non-Recyclable or Organic. As the Waste Classification dataset was primarily gathered via web-crawling we curated a subset of the images and placed them within the (existing) trash category or in the (newly created) organic category.
Given the limited availability of annotated recyclables datasets, we will also look to provide ongoing enhancement of training data via incorporating a “user upload” capability into the application that allows end-users to directly annotate and submit images.
| Dataset | Labels | Quality |
|---|---|---|
| TrashNet | cardboard, glass, metal, paper, plastic, trash | Good |
| Waste Classification v2 | recyclable, non-recylcable, organic | Average/Poor |
| User Provided | cardboard, glass, metal, paper, plastic, trash, organic & other | Unknown |
Model Selection
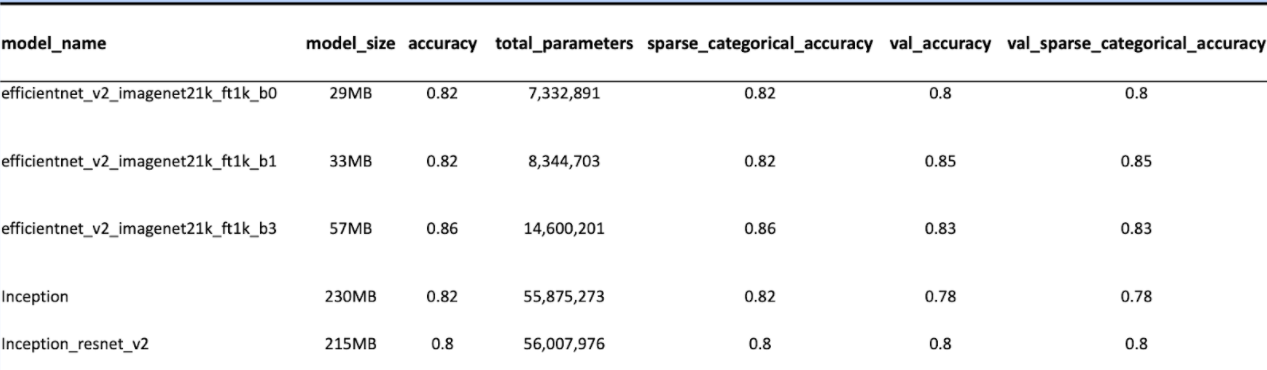
Several different transfer models were assessed for both size and performance. Best performing models are listed below:
Additionally several hyper-parameters were modified through-out experimentation including:
| Parameter | Optimized Value |
|---|---|
| Training/Validation Split | 80/20 |
| Decay Rate | 0.5 |
| Learning Rate | 0.01 |
| Max Epochs (w/ Early Stopping) | 15 |
| Kernel Weight | 0.0001 |
| Drop Out Weight | 0.2 |
Model build pipeline utilizes both Early Stopping as well as a LearningRateScheduler to achieve maximum accuracy without overfitting.
optimizer = keras.optimizers.SGD(learning_rate=learning_rate)
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
es = EarlyStopping(monitor="val_accuracy", verbose=1, patience=3)
lr = keras.callbacks.LearningRateScheduler(
lambda epoch: learning_rate / (1 + decay_rate * epoch)
)
Top layers added to downloaded transfer model were defined as:
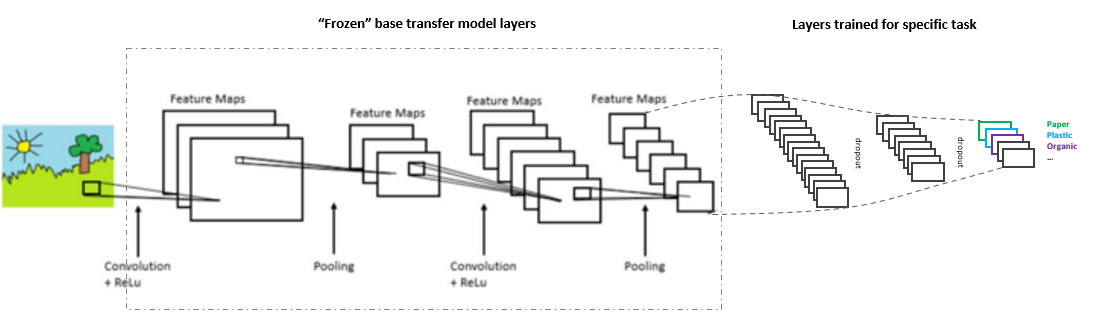
- Transfer Layer Base (non-trainable)
- Dense Layer (124, relu)
- Dropout Layer
- Dense Layer (64, relu)
- Dropout Layer
- Dense Layer (# classes, none)
Current production model was selected to be https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_b1/classification/2 based on performance and size characteristics. In particular the smaller size of the efficientnet models allow for a more cost effective architecture were model inference could be hosted on small resources due to lower memory requirements. This ultimately saves platform cost but also improves inference speed for a better use-experience.
Model Pipeline
An end-to-end training pipeline was implemented on the Luigi framework with the following DAG structure:
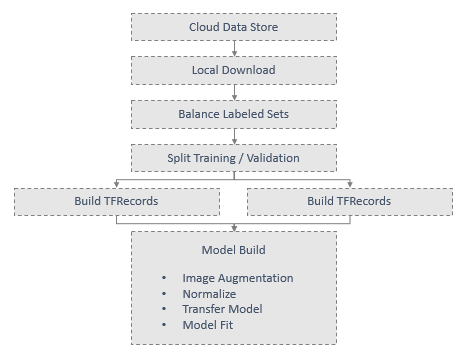
A Tensorflow based pipeline is used to process the TFRecords, augment, normalize, build and fit model. Model build results are stored in MLFlow via experimentation API and model registry API in order to allow a central application appraoch for model lifecycle management:
mlflow.log_param("model_origin", "efficientnet_v2_imagenet21k_ft1k_b1")
mlflow.log_param("decay_rate", decay_rate)
mlflow.log_param("learning_rate", learning_rate)
mlflow.log_param("num_classes", num_classes)
history = training_results.history
mlflow.log_metric("accuracy", history["accuracy"][-1])
mlflow.log_metric("val_loss", history["val_loss"][-1])
mlflow.log_param("epochs", len(history["accuracy"]))
# Log label mapping for retrieval with model:
mlflow.log_artifact(label_mapping)
mlflow.keras.log_model(
model, "model", registered_model_name="ciri_trashnet_model"
)
The Model Pipeline is deployed as a Kubernetes CronJob scheduled to run weekly. Models runs will be logged as subsequent model versions which can optionally be updated to “production” as desired by Application admins:

Deployment Architecture
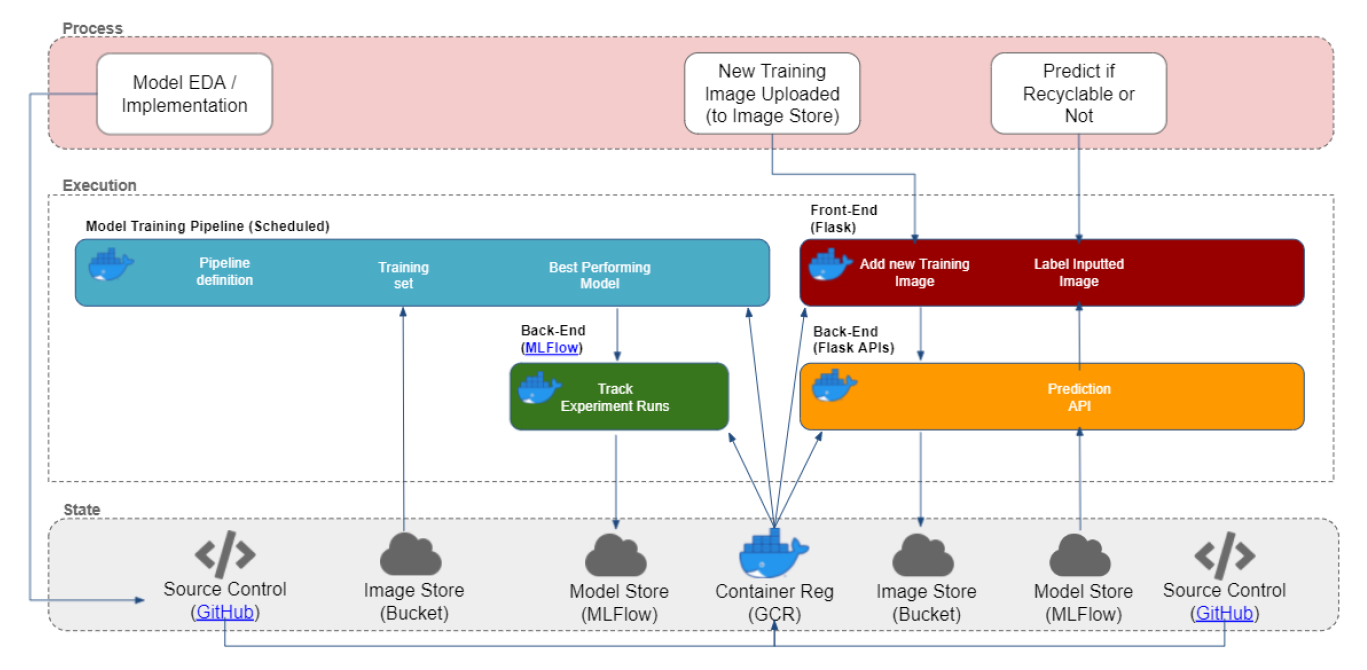
The CIRI Application is composed of multiple Services deployed on Kubernetes. By deploying on Kubernetes the CIRI application has significant resiliency and scalability “built-in” with an automated monitoring of Deployment health, and ability to auto-scale replicas of Deployments as needed.
| Services | Type | Description |
|---|---|---|
| mlflow | LoadBalancer | Provides intra-cluster and external access to the MLFlow Experiment Tracking and Model Repository services. |
| api | NodePort | Provides backend APIs that enable IO operations on training data-set as well as execution of predictions. |
| ui | NodePort | Provides an HTML based front-end for user interaction with application. |
| Deployments | Description |
|---|---|
| mlflow | Deployment of ciri_mlflow:latest Docker container. |
| api | Deployment of ciri_apis:latest Docker container. |
| ui | Deployment of ciri_frontend:latest Docker container. |
Additionally a CronJob is deployed to Kubernetes to run the model-pipeline weekly. Alternatively a model-pipeline “run once” Pod can be launched if an adhoc training run is desired:
| Pods | Description |
|---|---|
| model-pipeline | Deployment of model training pipeline via ciri_model_pipeline:latest Docker container. Pod runs one time and executes download of raw training images from Cloud Storage, processing/transformation of image files, training of model and registration of model in MLFlow model registry. |
Kubernetes Infrastructure
Ingress to the Kubernetes-hosted application is provided via Kubernetes ingress-nginx controller. Controller mappings are provided via the following definitions:
| Rule-Path | Service |
|---|---|
| /* | ui:8080 |
| /api/* | api:8080 |
Access to mlflow services is provided via external_ip:5000 as a hosted LoadBalancer component.
Application currently is designed for 2 node-pools to reflect a varied compute requirement for “always-on” application hosting vs. more intensive training:
| Node Pool | Description |
|---|---|
| default-pool | Always on pool that runs application services including mlflow, ui and api via default e2-medium instances. |
| training-pool | Auto-scaling pool of higher memory machines (e2-highmem-4) to execute training pipeline. |
The application also leverages two cloud storage resources:
| Cloud Storage | Name | Description |
|---|---|---|
| Image Store | canirecycleit-data | Provides storage of raw images used as input for training where “folders” reflect the classification. |
| Artifact Store | canirecycleit-artifactstore | Stores serialized metadata and model files from execution of model-pipeline. |
Initial Kubernetes (GKE) cluster provisioning can be executed via Ansible or shell scripts to enable an automated approach to infrastructure provisioning.
Application Deployment & Updating
Individual deployment containers as well as deployment of Kubernetes application are automatically executed via GitHub Actions. K8s deployment Action can be found here.
For individual Dockerized components (e.g. ciri_apis:latest the docker container is built on all merges of new code to master branch and made available via the GitHub Container Registry as a public image (no secrets or confidential information is stored within the Image).
For deployment of Kubernetes application (ciri_app) a request for deployment is generated with all changes merged to master branch.

Requests must be approved by an repository team member that is autorized for approval of the production environment. When approved, the Deployment Action will either deploy all components or patch existing components depending on if components already exist or not within cluster.
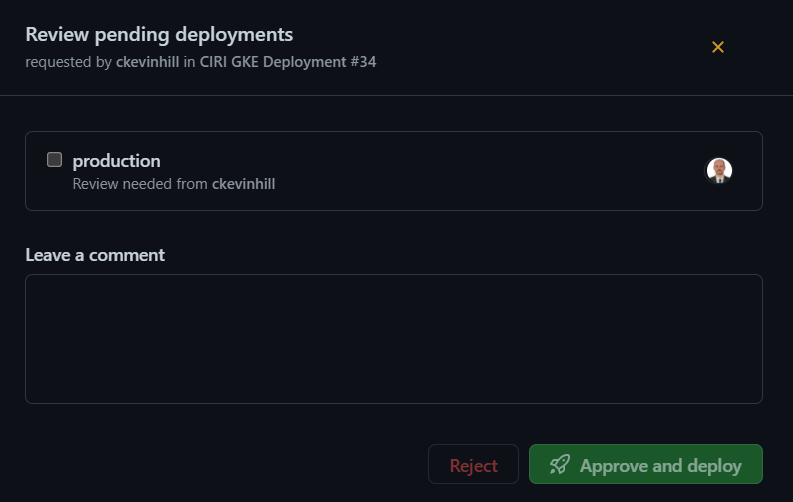
Deployments are set to pull new images so latest component Docker containers will be used on Deploy or Patch. Service Account (SA) secrets for deployment operations are stored within GitHub Environment Secrets for security purposes.
Application Usage & Screenshots
Application Home Page
A very simple MVP homepage that provides access to the core functionality to take a picture/upload an image for classification. Additional navigation links are available to Upload a new image (particularly helpful if image has been miscategorized) and to learn more About the application - including links to the application GitHub repository.
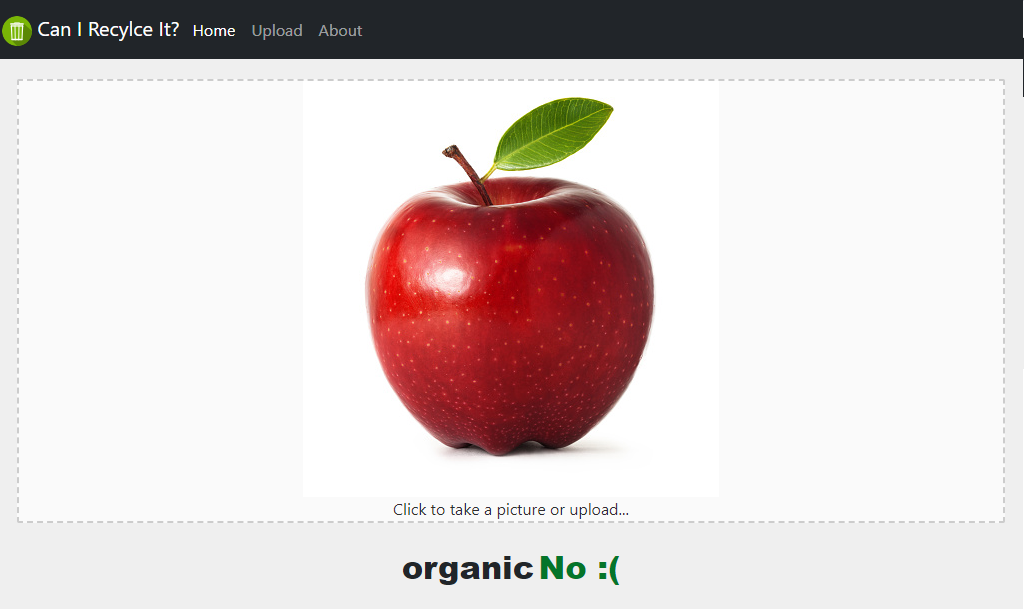
Example of an Organic item is not recylcable:
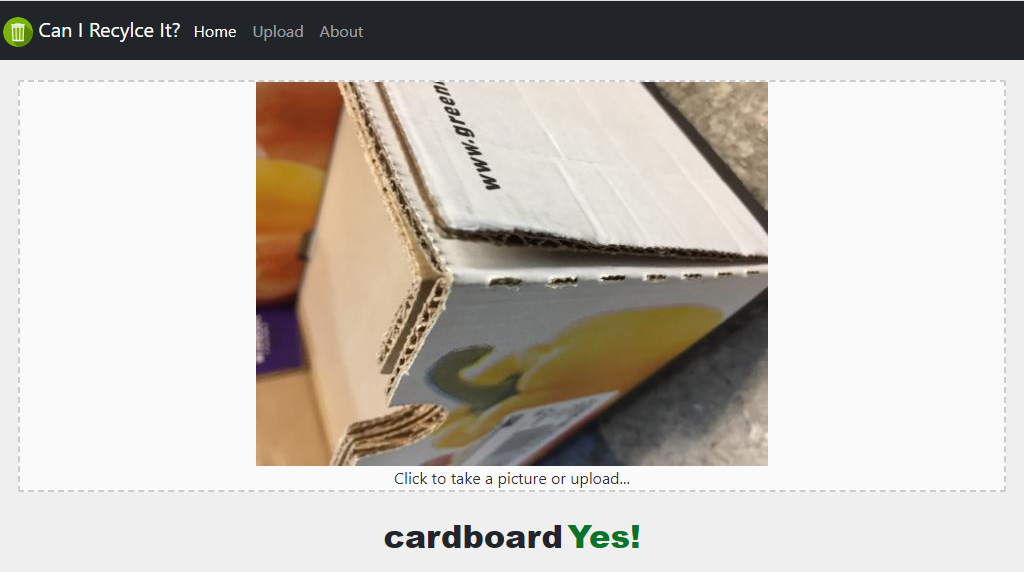
Example of a Cardboard item that is recycable:
Application Upload Page
Given that recyclables-annotated image data is relatively limited and of varied quality we determined that it was necessary to provide an ongoing way for users to enrich the annotated data-set so a basic upload form is provided to add new images to the CIRI Image data-store. The form provides a drop-down to select from all defined classification categories as well as a catch-all “other” category.
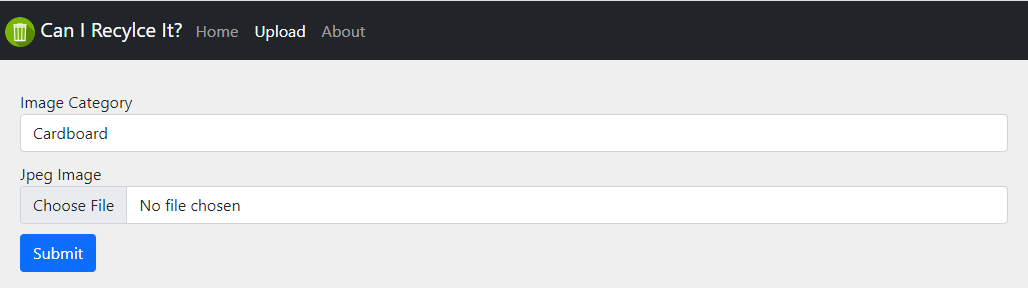

Models are retrained weekly to take advantage of any newly uploaded images that have been added to the data-store.
Model Management (MLFlow)
Weekly (or manually triggered) model builds are stored using MLFlow for both model build experiment tracking as well as model serialization as a model repository. This allows continual training and model performance metric capture but an operationally controllable approach for “promoting” experimental models into Production. CIRI administrators can log into the MLFlow interface, view models that are available for use and then move that Model through a lifestage (staging, production, archival) as part of the application management process - all without having to redeploy any application code.
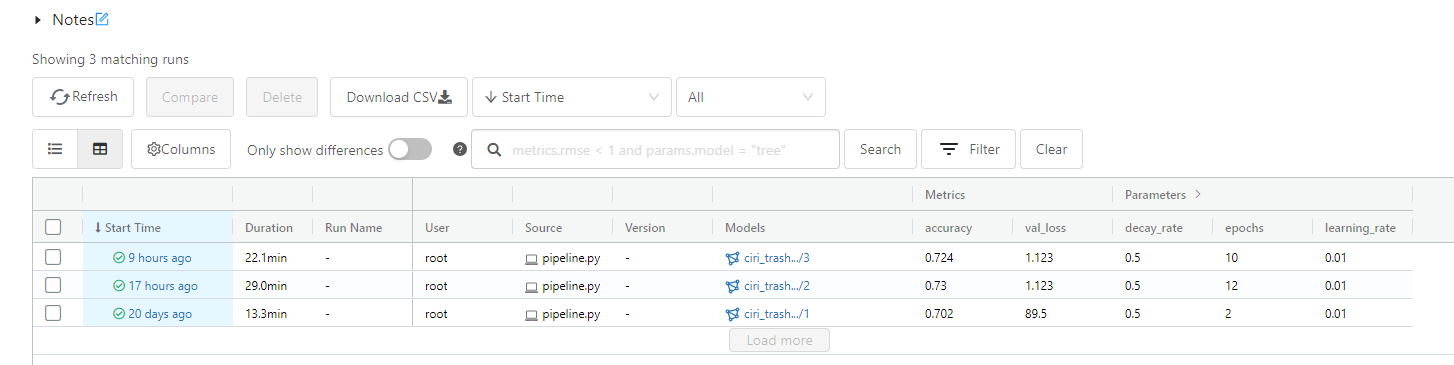
History of model run experiments:
Current model registry versions in model lifecycle stages:
