Generations of Analytic Value Creation
There are at least 5 distinct generations of analytic value creation - i.e. ways in which data has be used to create value for the enterprise. Each of these generations is spurred by a disruptive technology paradigm that either enables more powerful analytics or increased analytic democratization.
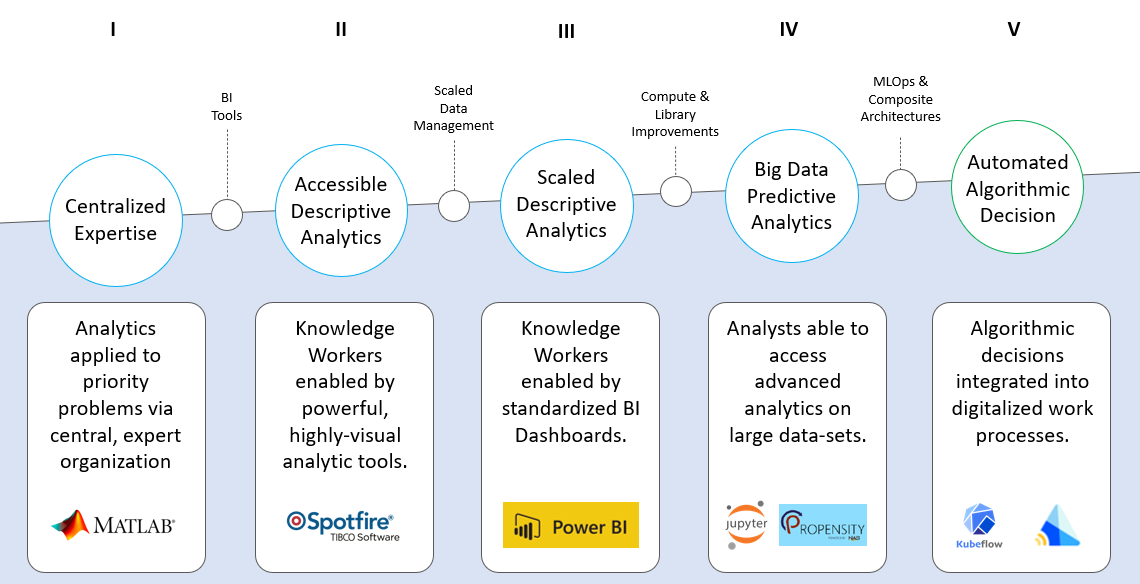
Generation Characteristics
Centralized Expertise (1960s+)
The first generation was characterized by centralized, expert organizations that had responsibility for applying statistical methods to critical business problems. These teams were highly trained (PhDs) and proficient in Statistical understanding and modeling. Projects were approved for work via executive management given the limited resource pool. Work was often done in statistical tools (MatLab, Fortran or via mainframe).
Accessible Descriptive Analytics (1990s+)
The second generation was brought about via the introduction of user-friendly, Business Intelligence (BI) tools. Tools like Tableau & Spotfire introduced real-time data transformation, visualization and regression capability to Analytic organizations. The ability to leverage data to drive inights was vastly expanded and could be embedded within line businesses. The value of data became more apparently as it was more accessible and reapplicable to more business problems.
Scaled Descriptive Analytics (2000s+)
The third generation saw more focus on creating high quality data through centralized data management. In conjunction with the creation of enterprise data-stores there is a shift from ad-hoc line business driven visualization to a more standardized (often web-based) reporting approach. Knowledge workers are able to directly mine data via Dashboards and interactive charts that have been curated by Analysts.
Big Data Predictive Modeling (2015s+)
The fourth generation introduced new capabilities (e.g. Hadoop, Spark, Jupyter) to process and model Big Data that was accumulated via digitization of processes and increased consumer device usage/tracking. This generation also introduced a more centralized “Data Science” organization with a mix of statistical and computer science skills but quickly spun off more self-service functionality via AutoML solutions, cloud-native tools (e.g. Big Query), and workflow UIs (e.g. Knime Big Data).
Automated Algorithmic Decision Making (2020s+)
The fifth (and currently evolving) generation focuses on introducing predictive and recommendation functionality directly into business processes. This further elevates data-driven decision-making by building on the computer science foundations of Data Science to provide application-centric (instead of analyst-centric) delivery of analytic value. This generation sees the introduction of DevOps best practices as well as standardized approaches to model deployment and operation via “AI Factories”.
Generations 1-to-4 vs. Generation 5
While Generatins 1 to 4 are fairly consistent - with some variation in level of democraticization and specific tools used - there is a marked difference vs. Gen 5 which is very platform-focused. Some examples of differences include:
| Gens 1-4 | Gen 5 |
|---|---|
| Value delivered via Analyst | Value delivered via Process |
| Executed as One-off Projects | Executed as Analytic Product (API) |
| Individual Contributor Approach | Part of End-to-End Application |
| Deliver “perect” | Deliver MVP and iterate |
| No operational concern | Heavy operation focus |
| Desktop environment | Deployed to cloud environment |
As a result of this change of focus, Analytic & Data Science organizations need to introduce new skills focused on MLOps/DevOps basics and work with AI Engineering and Cloud COE teams to create capability to enable standardized development and deploymnet of algorithms.